
Künstliche Intelligenz und Machine Learning mit Quantencomputern: Nur ein Superhype?
Künstliche Intelligenz und Machine Learning sind in aller Munde. Unser Alltag wird immer mehr durch sie bestimmt, sowohl im Offensichtlichen als auch im Verborgenen. Viele Branchen können sich gar nicht mehr erlauben Investitionen in Künstliche Intelligenz und Machine Learning zu ignorien. Staaten treiben mit Milliarden an Fördergeldern die Erprobung neuer Möglichkeiten voran i, und große gesellschaftliche Umbrüche stehen uns bevor.
Mit anderen Worten: Künstliche Intelligenz und Machine Learning ist vielleicht das Hype-Thema unserer Tage schlechthin.
Einer anderen Technologie, die ein gewaltiges Potential hat, habe ich diese Webseite gewidmet: Den Quantencomputern.
Was passiert also wenn ein Hype auf einen anderen Hype trifft?
Vorsichtig sein, sagt uns unser Instinkt. In diesem Artikel gebe ich Ihnen einen realistischen und aktuellen Lagebericht zu dem Thema. Wie angebracht diese Vorsicht ist, beweist die folgende Episode.
Eine Teenagerin schreckt die komplette Forschergemeinde auf (Teil 1)
Juni 2018, University of California in Berkeley: Eine Woche lang beraten führende Wissenschaflter für Quantencomputer-Algorithmen auf der Konferenz „Challenges in Quantum Computation“ über die Herausforderungen vor denen die aktuelle Forschung steht.
Am Ende der Konferenz bittet Scott Aaronson, von der University of Texas in Austin und einer der führenden Köpfe der Quantencomputer-Szene, einige Teilnehmer zu einer Extraschicht in einer dringenden Angelegenheit. Die Forscher treffen sich in der Folgewoche wieder. Unter ihnen sind auch Iordanis Kerenidis und Anupam Prakash.
Zwei Jahre zuvor hatten die beiden Forscher einen Algorithmus für ein Quanten-Empfehlungssystem entwickelt ii. Empfehlungssysteme ermitteln Vorlieben von Kunden anhand ihrer Bestellhistorie und bilden häufig das Herzstück von Bigdata-Unternehmen wie Amazon oder Netflix.
Der neue Algorithmus von Kerenidis und Prakash hatte in der Zwischenzeit eine enorme Aufmerksamkeit in der Forschergemeinde bekommen. Er war einer der ersten Quanten-Algorithmen, der speziell auf eine reale Anwendung im Bereich Bigdata und Machine Learning zugeschnitten war und erwiesenermaßen eine exponentielle Beschleunigung gegenüber allen bekannten Algorithmen für herkömmliche Computer besaß.
Am Morgen des 18. Junis tritt Aaronsons junge Studentin Ewin Tang vor die erlesene Runde und beginnt einen Vortrag über Kerenidis und Prakashs Arbeit.
Und langsam dämmert den verblüfften Anwesenden die bittere Tragweite von Ewin Tangs Ausführungen … (Teil 2 folgt weiter unten).
Künstliche Intelligenz und Machine Learning: Ein Kurzüberblick
Um die Episode zu beenden und überhaupt um diesen Artikel zu verstehen, müssen wir erst mal ganz von vorne anfangen. Was ist eigentlich Künstliche Intelligenz oder Machine Learning?
Eines der Hauptziele der klassischen künstlichen Intelligenz und des Machine Learnings ist es Daten zu struktieren und zu klassifizieren. Folgende Schwerpunkte gibt es dabei:
- Supervised Machine Learning, überwachtes Maschinelles Lernen: Dabei werden bekannte und bereits beurteilte Daten dafür verwendet, um neue Daten zu klassifizieren. Das Standardbeispiel hierfür sind die Deep Learning – Netzwerke. Ein Deep Learning – Netzwerk wird z.B. mit beurteilten Tierbildern gefüttert (Bild 1 = „Katze“, Bild 2 = „Vogel“, Bild 3 = „Katze“, …). Nach einer längeren Anlernphase ist das Netzwerk optimiert bzw. trainiert und in der Lage neue, unbekannte Bilder richtig einzuordnen.
- Unsupervised Machine Learning, unüberwachtes Maschinelles Lernen: Dabei wird nach Zusammenhängen und Gruppen in Rohdaten gesucht, ohne dass irgendwelche Zusatzinformationen zu diesen Daten bekannt wären. Dadurch wird versucht, die Rohdaten auf das „Wesentliche“ zu reduzieren.
- Semi-supervised Machine Learning, teilüberwachtes Maschinelles Lernen: In einer Datenmenge sind einige Daten bereits beurteilt und einige noch nicht. Anhand der zusätzlichen Informationen wird versucht, die gesamte Datenmenge besser zu strukturieren und zu gruppieren. Dies geschieht insbesondere über statistische Methoden.
- Reinforced Machine Learning, bestärkendes Maschinelle Lernen: Das Verhalten eines Softwareagenten wird mittels „Belohnung und Bestrafung“ immer weiter verbessert.
Die ersten beiden Schwerpunkte erläutere ich Ihnen im Weiteren etwas genauer. Dabei stelle Ihnen einige Algorithmen für Quantencomputer vor, von denen man sich eine Beschleunigung gegenüber Methoden für herkömmliche Computer erhofft.
Wie Machine Learning – Algorithmen Rohdaten sehen
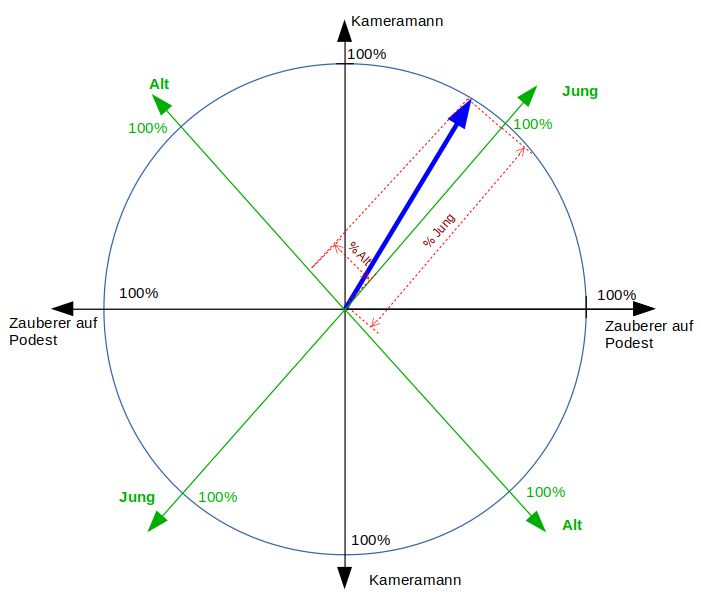
Um Rohdaten für das Machine Learning aufzubereiten, hat es sich bewährt, diese Daten als Zeiger bzw. „Vektoren“ in riesigen, hochdimensionalen Datenräumen darzustellen. Und mit „riesig“ meine ich jetzt nicht so etwas, wie die „grenzenlosen Weiten des Weltalls“, sondern einen abstrakten Hyperraum mit vielen, vielen Dimensionen (also Achsen, die jeweils senkrecht aufeinander stehen). Hier wieder mein Hinweis: Versuchen Sie erst gar nicht, sich mehr als drei senkrechte Achsen räumlich vorzustellen (nämlich Höhe, Länge, Breite). Wir Menschen können es einfach nicht! Die Mathematik hat damit allerdings überhaupt keine Probleme. Sie kann mit beliebig vielen Dimensionen arbeiten, sogar mit unendlich vielen.
Ein Bild mit 16 * 16 Pixeln, wird so z.B. als ein Zeiger in einem Datenraum mit 16 * 16 = 256 Dimensionen dargestellt. Falls Pixel Nr. 194 in dem Bild auch nur etwas grau ist, dreht sich der Datenzeiger etwas in die Richtung der 194. Achse und zwar umso mehr, je schwarzer der Punkt im Bild ist.
Machine Learning mit Quantencomputern
Solche Datenräume stellen für herkömmliche Computer einen gewissen Aufwand dar: Um z.B. einen Zeiger in einer Ebene mit auch nur zwei Dimensionen (also wie ein Uhrzeiger) mit einer Genauigkeit von 0.1% darzustellen, braucht Ihr Computer etwa 20 Bits. Um diesen Zeiger zu verändern, in dem er z.B. gedreht wird, muss auf jedes dieser 20 Bits ein größere Anzahl an elementaren Bit-Operationen ausgeführt werden.
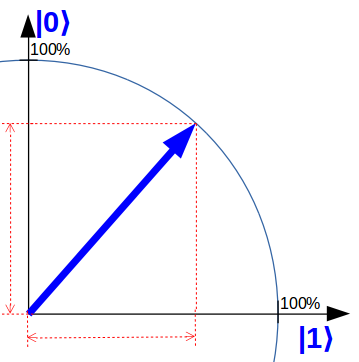
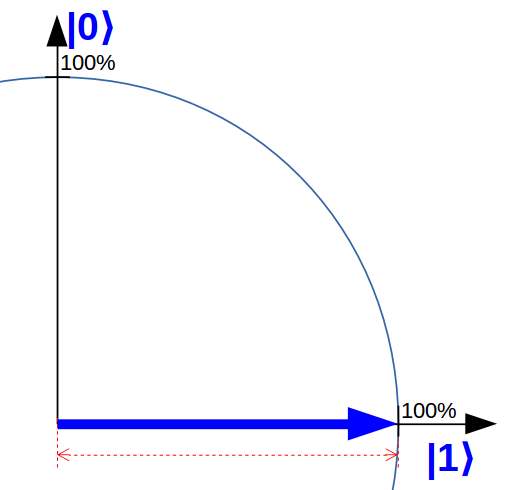
Ein Quantencomputer besitzt solche Zeigerdarstellungen von Natur aus. In meinem Artikel „Das Qubit und ein Magier bei Britain has Got Talent“ erkläre ich Ihnen, dass sich ein Qubit selbst, etwas vereinfacht, wie ein Zeiger in einer Ebene verhält. Die Achsen heißen in dem Fall „0“ und „1“. Im Prinzip kann unser Zeiger-Beispiel also mit einem einzigen Qubit dargestellt werden.
Zeiger-Operationen sind prinzipiell ebenfalls direkt im Quantencomputer eingebaut und erfordern nur wenige Qubit-Operationen bzw. Quantengatter.
Aber es geht noch viel besser: Dieser Vorteil eines Quantencomputers verstärkt sich prinzipiell, je größer bzw. hochdimensionaler die Datenräume werden.
Und zwar exponentiell, also quasi explosionsartig!
Der Grund dafür ist, dass ein Quantencomputer seine potentielle Leistungsfähigkeit mit jedem weiteren Qubit verdoppelt. Dieses Quanten-Phänomen beschreibe ich genauer in meinem Einführungsartikel „Quantencomputer einfach erklärt“.
Unsupervised Machine Learning mit Quantencomputern
Dieser exponentielle Quanten-Vorteil ist bereits ein Hauptargument vieler Quanten-Algorithmen für Machine Learning.
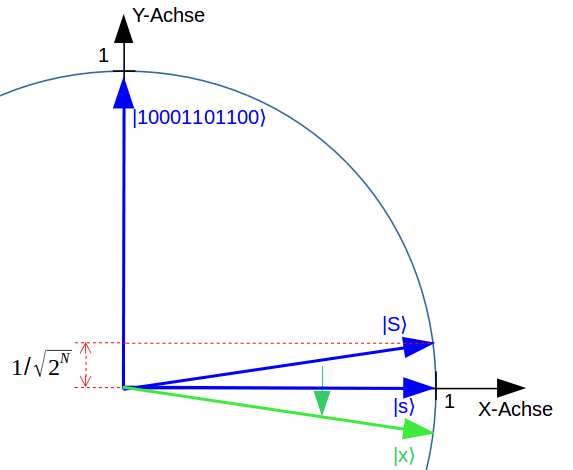
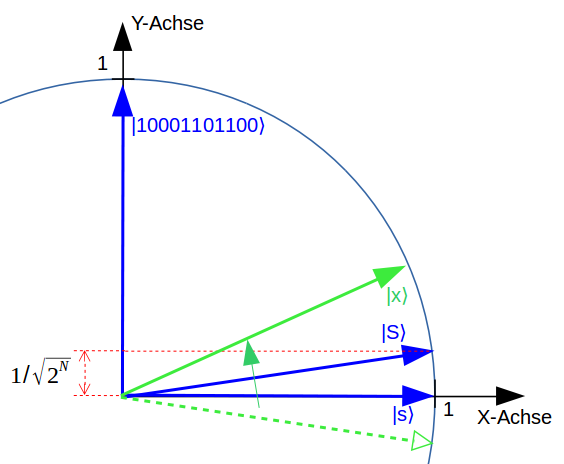
Auch klassische Algorithmen können viele Information über Rohdaten ermitteln, wenn sie als Zeiger in einem Datenraum dargestellt werden. Über die bloße „räumliche“ Verteilung ihrer Zeigerspitzen in dem riesigen Datenraum können sie z.B. zu Gruppen zusammengefasst werden.
Ein Quantencomputer rechnet prinzipiell anders als ein herkömmlicher Computer. Abstände von zwei Zeigerspitzen können über einen kleinen Rechen-Trick allerdings auch mit einem Quantencomputer berechnet werden: Dabei werden die Zeiger in zwei neue, sehr spezielle Zeiger umgewandelt. Der Abstand der ursprünglichen Zeigerspitzen wird dann aus dem Winkel der zwei neuen Zeiger ermittelt iii.
Die Hauptkomponentenanalyse mit Quantencomputern
Ein weiterer interessanter Algorithmus für das klassische Unsupervised Machine Learning ist die Hauptkomponentenanalyse bzw. Principal Component Analysis (PCA) iv. Die PCA verwendet für die Rohdaten ebenfalls den Datenraum. Darin werden die Datenpunkte bzw. die Zeigerspitzen als Bausteine eines massiven, starren Körpers interpretiert. Für diesen Körper können dann „mechanische Eigenschaften“ ermittelt werden. Die Hauptdrehachsen des Körpers (bei einem Spielzeugkreisel wäre die Hauptachse z.B. die senkrechte Drehachse des Kreisels) sind dann gerade die Hauptkomponenten des Datensatzes. Die PCA reduziert den starren Köper des Datensatzes im Prinzip auf einfachere geometrische Formen, mit ähnlichen mechanischen Eigenschaften. Die Rohdaten werden dadurch ebenfalls auf ihre Hauptkomponenten-Anteile reduziert.
Für die PCA wurde ebenfalls ein Quanten-Algorithmus mit einer exponentiellen Beschleunigung gefunden v. Dieser nutzt eine ganzen Latte von weiteren vielversprechenden Quanten-Algorithmen aus. Unter anderem der „Quantum Matrix Inversion“ oder geläufiger als „HHL-Algorithmus“ bezeichnet (nach seinen Autoren Harrow-Hassidim-Lloyd) vi. Der HHL-Algorithmus wurde 2008 gefunden und basiert selbst auf mehreren Algorithmen, die ich auf quantencomputer-info.de teilweise schon vorgestellt habe. Er ist in der Lage sogenannte lineare Gleichungssysteme exponentiell schneller zu lösen als alle herkömmlichen Algorithmen. Solche Gleichungssysteme so extrem häufig, dass der HHL-Algorithmus mittlerweile einer der Eckpfeiler der Forschung für Quanten-Algorithmen ist.
Quantencomputer und Machine Learning: Lese das Kleingedruckte …
Die spektakulären Quanten-Algorithmen, die ich bisher erwähnt habe, haben allerdings mindestens einen ganz gewaltigen Haken: Wie kommen die klassischen Rohdaten in den Quantencomputer?
Ein Quantencomputer ist in der Lage die Rohdaten exponentiell effizient darzustellen, soweit korrekt. Trotzdem müssen sie aber erstmal irgendwie in den Quantencomputer gelangen. Wenn das nicht mindestens genauso effizient erfolgen kann, ist der ganze Vorteil des superschnellen Quanten-Algorithmus bereits ganz am Anfang wieder hinfällig.
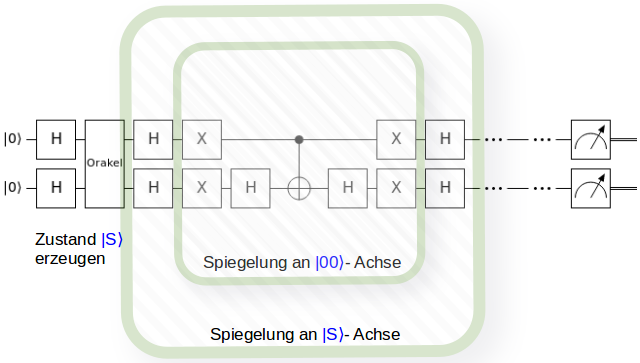
Wie dies erfolgen könnte wurde natürlich auch schon untersucht. Das vielversprechendste Konzept dafür nennt sich Quantum Random Access (QRAM) vii. QRAM hat aber auch einen Haken: Es gibt ihn noch nicht und wäre auch eine zusätzliche Quanten-Hardware, um die man sich kümmern müsste. QRAM besitzt eine Baumstruktur, an deren Knoten bzw. Verästlungen Quantenweichen sitzen, die jede Laderoutinen entweder in den linken oder in den rechten Seitenast weiterleiten. An den Blättern des Baumes befinden sich dann Informationen über die Zeiger der Rohdaten. Die Quantenweichen besitzen, anders als die Qubits, nicht zwei Quantenzustände, sondern drei. Von diesen Zuständen muss der Grundzustand besonders stabil sein. Die Entwicklung von QRAM ist noch völlig offen.
Ein weiterer Haken vieler Quanten-Algorithmen für Machine Learning: Wie Sie erfahren haben, basieren sie auf einer Mehrzahl zusätzlicher grundlegender Quanten-Algorithmen. Obwohl diese sehr spannend sind und großes Potential besitzen, wie z.B. der HHL-Algorithmus: Sie alle setzen die ein oder andere Bedingung voraus. Z.B. benötigen sie sehr große Quantencomputer oder eine gewisse Datenstruktur oder halt QRAM.
In Summe zu viele Fragezeichen für den eingangs erwähnten Scott Aaronson von der University of Texas. 2015 schrieb er einen Weckruf an seine Forscher-Kollegen: „Quantum Machine Learning Algorithms: Read the Fine Print“ viii und erhielt damit viel Zuspruch.
Eine Teenagerin schreckt die komplette Forschergemeinde auf (Teil 2)
Hier kommt seine junge Studentin wieder ins Spiel:
Ein Jahr später veröffentlichten Iordanis Kerenidis und Anupam Prakash den eingangs erwähnten Algorithmus für ein Quanten-Empfehlungssystem. Er war vielleicht der erste Algorithmus, der viele dieser Einschränkungen berücksichtigte, für eine reale Anwendung im Bereich Bigdata und Machine Learning zugeschnitten war und eine exponentielle Beschleunigung gegenüber allen bekannten Algorithmen für herkömmliche Computer besaß.
Was noch fehlte, war der Nachweis, dass es tatsächlich keinen schnelleren klassischen Algorithmus geben konnte. Scott Aaronson war genau davon überzeugt. Im Herbst 2017 übergab er die Suche nach diesem Nachweis an seine außerordentlich talentierte und vielversprechende Studentin Ewin Tang, als Thema für ihre Bachelor-Arbeit.
Was Ewin Tang dann der verblüfften Gruppe namhafter Forscher im Juni 2018 auf der Konferenz „Challenges in Quantum Computation“ in Berkeley präsentierte, war der von niemanden für möglich gehaltene Negativ-Nachweis. Ein neuer superschneller Algorithmus für Empfehlungssysteme sehr ähnlich wie der Quanten-Algorithmus Kerenidis und Prakash: Aber für herkömmliche Computer!
Erst später informierte Tangs Mentor Scott Aaronson die Forschern über ein weiteres kleines aber interessantes Detail zu dieser Entdeckung: Zum Zeitpunkt ihres Vortrages war Ewin Tang gerade einmal 18 Jahre alt ix.
„Quantum-inspired …“: Neue klassische Algorithmen für Machine Learning
Seit ihrer Entdeckung hat Ewin Tang eine Reihe von Artikeln über klassische Algorithmen mit dem Etikett „Quantum-inspired … “ veröffentlicht x. Diese machen die bereits gefunden Quanten-Algorithmen zwar nicht hinfällig, schränken aber wohl ihren Nutzen noch weiter ein xi.
Dabei ist Tangs Hauptargument das Folgende:
Wie viele andere Quanten-Algorithmen für Machine Learning und Linearer Algebra, geht auch der Algorithmus für das Quanten-Empfehlungssystem davon aus, dass die Datengrundlage (die Matrix von Benutzern und deren bekannten Produktvorlieben) Quantencomputer-gerecht und supereffizient in z.B. einer QRAM-Struktur abgelegt ist.
Tang argumentiert nun: Wer in der Lage ist, die Rohdaten in einer so aufwendigen Struktur von Quantenüberlagerungen abzulegen, sollte erst recht in der Lage sein, die Rohdaten in einer klassischen „Sample-And-Query“-Struktur abzulegen. Diese Struktur ist Tangs Pendant zum QRAM, ihm sehr ähnlich und genauso effizient aufgebaut. Anstatt mit Quanten-Überlagerungen arbeitet diese Datenbank mit reiner Statistik.
Die Rohdaten werden dabei in Datenfragmente aufgeteilt. Diese Fragmente werden in der SQ-Struktur nach ihrer Signifikanz am kompletten Datensatz statistisch gewichtet und können von dort supereffizient abgerufen werden. Die komplexe Berechnung des Quanten-Empfehlungssystems ersetzt Tang durch eine clevere statistische Einzelrechnung mit zufällig ausgewählten Datenfragmenten gemäß ihrer Gewichtung. Da auch die statistische Signifikanz der Fragmente abgerufen werden kann (ihre „statistische Verteilung“), ist Tang in der Lage das gesuchte, exakte Endergbnis abzuschätzen: Als Mittelwert aus der Statistik dieser Einzelergebnisse und mit jedem zusätzlichen Einzelergebnis immer genauer.
Dank des Quanten-Parallelismus kann der Quanten-Algorithmus von Kerenidis und Prakash von Anfang an mit dem kompletten Datensatz und exakt rechnen. Die Messung des Endergebnisses ist dann allerdings von der Quanten-Statistik abhängig. Im Gegensatz dazu „mißt“ Tang also nur Fragmente der Rohdaten gemäß ihrer statistischen Signifikanz und das schon ganz am Anfang. Dadurch reduziert sie die Datengröße und somit den Rechenumfang exponentiell und komponsiert den fehlenden Quanten-Parallelismus.
Wer meint, dass sich jetzt so ziemlich jedes Bigdata-Unternehmen um Ewin Tangs – Algorithmen reißen müsste, wird etwas enttäuscht. Tang bewertet den Nutzen ihrer bisherigen Arbeit für reale Anwendungsfälle in ihrem Blog nur „verhalten positiv“ xii.
Trotz des „Negativ-Ergebnisses“ zeigt diese Episode auch, wie fruchtbar die neuen Denkansätze für Quantencomputer selbst für herkömmliche Computer sein können. Oder wie Matthias Troyer von Microsoft Research es formuliert hat: „Ein Quanten-Algorithmus für Null Qubits“.
Quantencomputer, Künstliche Intelligenz und Machine Learning: Die Suche nach neuen Algorithmen
Als Zwischenfazit können wir festhalten: Die Quantencomputer-Forschung hat für die Künstliche Intelligenz und für das Machine Learning bereits eine Reihe interessanter Algorithmen entwickelt, die aber ihren Geschwindigkeitsvorteil hauptsächlich aus Unterroutinen wie QRAM und dem HHL-Algorithmus beziehen.
Wann und ob diese überhaupt eingesetzt werden können, ist noch offen.
Erst vor ein paar Jahren hat man damit begonnen, nach ganz neuen Wegen für die Künstliche Intelligenz und für das Machine Learning mit Quantencomputern zu suchen. Und zwar nach solchen Wegen, die bereits mit den kommenden Generationen von Quantencomputer beschritten werden können. Für Letztere prägte der bekannte Quantencomputer-Forscher John Preskill den Begriff „Noisy Intermediate Scale Quantun Computers“ (NISQ): Fehleranfällige, mäßig skalierte Quantencomputer xiii.
Drei prominente Vertreter solcher Quanten-Algorithmen habe ich Ihnen Bereits in meinem Artikel „Anwendungen für Quantencomputer“ vorgestellt: Dem „Quantum Adiabatic Algorithm“ (QAA), dem „Variational Quantum Eigensolver“ (VQE) und dem „Quantum Approximate Optimization Algorithm“ (QAOA). Die aktuelle Forschung für das Machine Learning mit Quantencomputern versucht diese Konzepte für die eigenen Ziele anzuwenden.
Kommen wir aber erst mal zu dem zweiten wichtigen Schwerpunkt der klassischen Künstlichen Intelligenz und des Machine Learnings:
Supervised Machine Learning und Deep Learning
Ein Herzstück aktueller Algorithmen für künstliche Intelligenz und Machine Learning sind „tiefe“ neuronale Netzwerke (Deep Learning – Netzwerke). Historisch gesehen war das Ziel hier, die Neuronen und Synapsen im Gehirn irgendwie programmatisch nachzuahmen. Herausgekommen ist ein Netzwerk von Knotenpunkten, die über mehrere Schichten miteinander verbunden werden.
Quelle: https://de.wikipedia.org/wiki/Deep_Learning#/media/Datei:MultiLayerNeuralNetworkBigger_english.png

Anhand von beliebigen Eingabe-Daten (z.B. mit Bildern von der Ziffern „1“, Bildern von der Ziffer „2“, …) wird das Netzwerk so eingestellt bzw. „trainiert“, dass es möglichst das gewünschte Ergebnis erkennt (die Ziffer 1, 2, …) xiv. Wie die Rohdaten für die Eingabe aufbereitet werden, habe ich Ihnen weiter oben schon anhand des „Datenraumes“ erklärt.
Das klassische Deep Leaning wurde in den 1970er entwickelt aber erst 1986 durch den „Backpropagation-Algorithmus“ revolutioniert: Ein Algorithmus über den das gesamte Netzwerk mit jeder neuen Trainingsrunde besonders effizient nachjustiert werden kann. In den letzten 10-15 Jahren zog dann die Hardware nach und wurde leistungsstark genug für die komplexen Algorithmen. Das Zeitalter von Google und Social Media fügte dann den letzten fehlenden Baustein hinzu: Eine Informationsflut von beurteilten Rohdaten, mit denen die Neuronalen Netze trainiert werden können.
Wie beeindruckend gut das Deep Learning mittlerweile funktioniert, sehen wir z.B. an den selbstfahrenden Autos und an den Sprachassistenten. Warum das ganze Konzept aber so gut funktioniert ist bis heute tatsächlich noch nicht genau verstanden xv.
Quantencomputer: Netzstrukturen auf Stereoide
Aber wie kommen jetzt die Quantencomputer ins Spiel?
Auf der einen Seite haben wir also die Deep Learning – Netzwerke. Diese sind sehr komplexe, programmierte Netzstrukturen. Durch eine Trainingsphase werden sie so filigran eingestellt, dass sie neue unbekannte Eingabedaten erfolgreich beurteilen können.
Quantencomputer auf der anderen Seite, sind so etwas wie Netze „auf Stereoide“. In Quanten-Netzen können andersartige Strukturen wie selbstverständlich verwendet werden, die in „normalen“ Netzen nicht denkbar wären. Die Vermutung liegt nahe, dass Quantencomputer dadurch einen Mehrwert gegenüber herkömmlichen Computer erzielen können.
Wem dieser Ansatz zu vage ist, dem sei gesagt, dass die Geschichte der Computerwissenschaften voll von „Schaun wir mal“-Algorithmen ist, die sich in der Praxis unheimlich bewährt haben. Ein Beispiel sind gerade die Deep Learning – Netze selbst.
Edward Farhi und Hartmut Neven von Googles Quantum AI-Team, haben 2018 gerade solche neuronalen Quanten-Netze genauer untersucht, die auf die NISQ-Quantencomputer optimiert sind xvi. Diese Strukturen bauen unter anderem auf Farhis oben erwähnten QAOA-Algorithmus auf.
Dabei wendeten Farhi und Neven ihre Algorithmen auch auf den MNIST-Datensatz an. MNIST ist ein öffentlich zugänglicher Datensatz von 55.000 beurteilten Bildern. Jedes Bild zeigt eine handgeschriebene Ziffer zwischen 0 und 9. Die MNIST-Bilder sind der allgemein gebräuchliche Standarddatensatz für Deep Learning – Netze über den die verschiedenen Algorithmen einigermaßen objektiv miteinander verglichen werden können.
Farhi und Neven konnten ihr neuronales Quanten-Netz erfolgreich mit den MNIST-Bildern trainieren. Auf einem Quantensimulator mit gerade mal 17 Qubits! Das ist ein Achtungserfolg und ein erster vielversprechender Anfang. Quantencomputer verdoppeln im Prinzip mit jedem weiteren Qubit ihr Potential. Deshalb besteht die Erwartung, dass jeder neue Quantencomputer auch bei den neuronalen Quanten-Netze deutlich meßbare Verbesserungen erzielen kann.
Das Beispiel zeigt aber auch, wie weit der Weg noch ist, bis die Forschung konkurrenzfähige neuronale Quanten-Netzwerke, geschweige denn real überlegene neuronale Quanten-Netzen konstruiert hat. Einen möglichen Weg zeigen Farhi und Neven auch auf: Hybride Quanten-klassische neuronale Netze. Eine Kombination von klassischen Deep Learning – Netzwerken mit neuronalen Quanten-Netzen. Erstere bereiten die Eingabedaten in handlichere Formen auf. Letztere sollten in der Lage, diese reduzierten und speziell präparierten Daten auch mit wenigen Qubits weiter zuverarbeiten und das Gesamtnetzwerk mit den gewünschten Quanten-Effekten zu „würzen“.
Fußnoten
i https://www.kas.de/documents/252038/3346186/Vergleich+nationaler+Strategien+zur+F%C3%B6rderung+von+K%C3%Bcnstlicher+Intelligenz.pdf/46c08ac2-8a19-9029-6e6e-c5a43e751556?version=1.0&t=1559905070357: Studie „Vergleich nationaler Strategien zur Förderung von Künstlicher Ingelligenz“
ii https://arxiv.org/abs/1603.08675: „Quantum Recommendation Systems“, wissenschaftliche Arbeit von Iordanis Kerenidis und Anupam Prakash
iii https://arxiv.org/abs/1409.3097: „An introduction to quantum machine learning“, wissenschaftlicher Artikel von Maria Schuld et al
v https://arxiv.org/abs/1307.0401: „Quantum principal component analysis“, wissenschaftlicher Artikel von Seth Lloyd, Masoud Mohseni und Patrick Rebentrost
vi https://arxiv.org/abs/1802.08227: „Quantum linear systems algorithms: a primer“. Ein Einführungsartikel von des HHL-Algorithmus Danial Dervovic et al. inkl. Erläuterungen zu den Grundlagen auf denen er aufbaut.
vii https://arxiv.org/abs/0708.1879: „Quantum random access memory“, wissenschaftliche Arbeit von Giovannetti, Lloyd und Maccone
viii https://scottaaronson.com/papers/qml.pdf: „Quantum Machine Learning Algorithms: Read the Fine Print“, Artikel von Scott Aaronson
ix https://www.quantamagazine.org/teenager-finds-classical-alternative-to-quantum-recommendation-algorithm-20180731/
x https://arxiv.org/abs/1807.04271: „A quantum-inspired classical algorithm for recommendation systems“, https://arxiv.org/abs/1811.00414: „Quantum-inspired classical algorithms for principal component analysis and supervised clustering“ oder https://arxiv.org/abs/1811.04909: „Quantum-inspired sublinear classical algorithms for solving low-rank linear systems“ von Ewin Tang et al.
xi https://www.youtube.com/watch?v=P2Bucnq_ap0: In dem Video „TCS+ talk: Ewin Tang“ erläutert Ewin Tang ihren Algorithmus. Insbesondere stellt sie die Vermutung auf, dass man keine exponentielle Beschleunigung für niedrigdimensionale Datenzeiger erwarten darf. Das soll heißen: Rohdaten, die nur an vergleichsweise wenigen Stellen von Null verschieden sind.
xii https://ewintang.com/blog/2019/01/28/an-overview-of-quantum-inspired-sampling/: Ein sehr hilfreicher Übersichtsartikel von Ewin Tang in ihrem Blog über ihre Veröffentlichungen.
xiii https://arxiv.org/abs/1801.00862: „Quantum Computing in the NISQ era and beyond“, Vortragvorlage von John Preskill zur Konferenz „Quantum Computing For Business“ in 2017.
xiv http://neuralnetworksanddeeplearning.com/: Das Online-Buch von Michael Nielsen ist eine wunderbare Einführung für das Deep Learning. Interessanterweise ist Michael Nielsen außerdem der Co-Author des Standard-Lehrbuches für Quantencomputer „Quantum Computation and Quantum Information“. Man könnte meinen, dass er für den Forschungszweig Quantencomputer und Machine Learning prädistiniert ist. Aber anscheinend widmet sich Nielsen mittlerweile ganz anderen Themen, die weder mit dem einem noch mit dem anderen zu tun haben.
xv https://www.quantamagazine.org/new-theory-cracks-open-the-black-box-of-deep-learning-20170921/: „New Theory Cracks Open the Black Box of Deep Learning“, Artikel auf Quantamagazine
xvi https://arxiv.org/abs/1802.06002 : „Classification with quantum neural networks on near term processors“ wissenschaftlicher Artikel von Edward Farhi und Hartmut Neven.












{kind=link}